Hello everyone,
Ages since last post 😀 on Thursday July 14th I gave a talk about my paper “Modifying MCTS for Humanlike Video Game Playing” with Aaron Isaksen, Andy Nealen, and Julian Togelius at IJCAI16. Thanks to Aaron, he captured a video of my talk. Here is it:
Also we did a poster for the conference which looked amazing. Here is the poster:
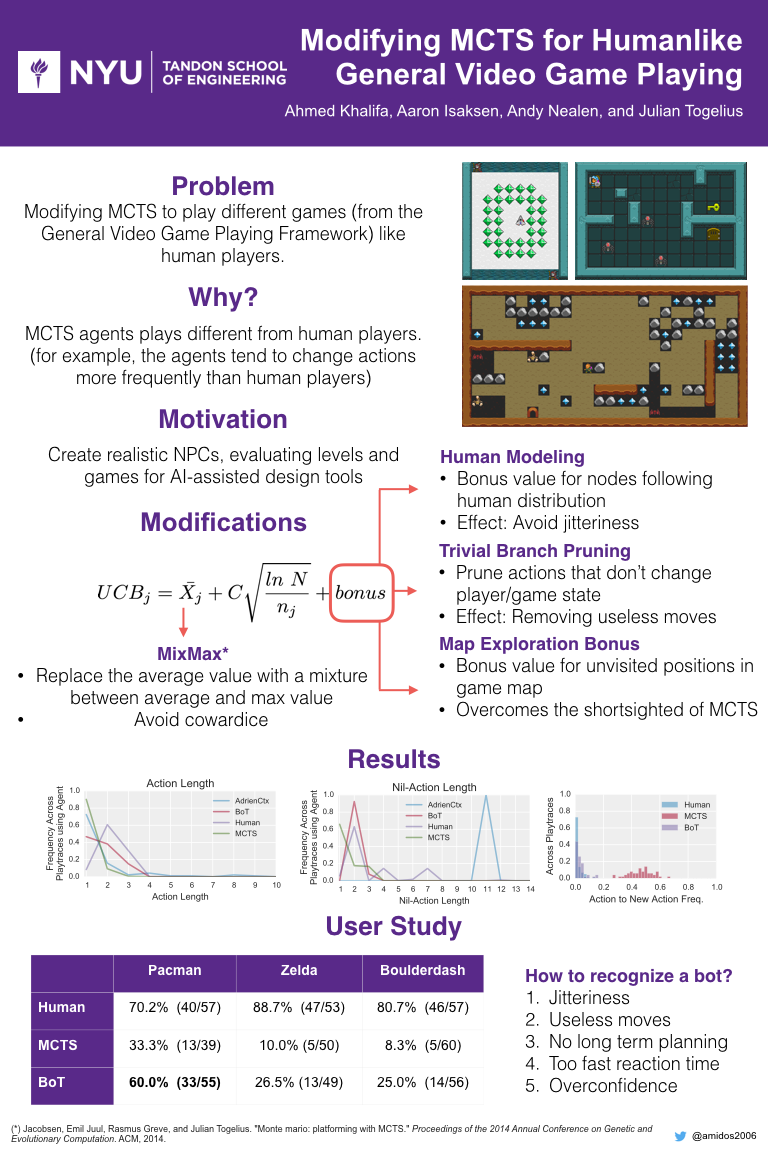
If the video is not clear, I am posting the slides here with my comments:

Hello everyone, I am Ahmed Khalifa, PhD student at NYU Tandon’s School of Engineering. Today I am gonna talk about my paper “Modifying MCTS for Humanlike Video Game Playing”.

We are trying to modifying Monte Carlo Tree Search algorithm to play different games like human player. We are using General Video Game Playing Framework to test our algorithm.
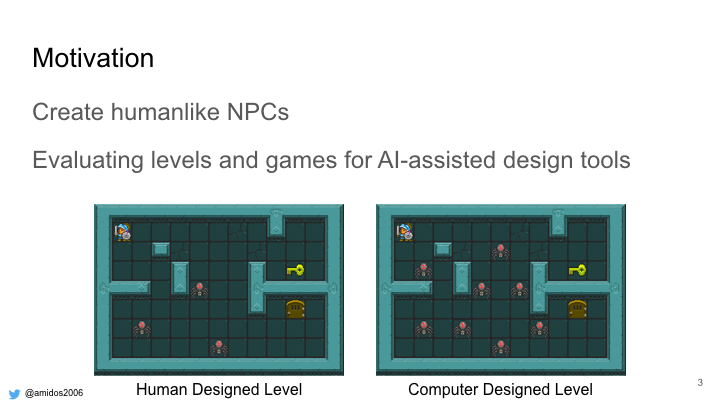
Why do we need that? One important reason is create humanlike NPCs. One of the reason people play Multiplayer games is the lack of realistic NPCs to play with or against. Also evaluating levels and games for AI-assisted tools. For example if you gave these two levels to a human, he will pick the one on the left as its playable by human while the one of the right is super difficult, it might even be impossible to be played.

Before we start, whats general video game playing which we are using its framework. Its a competition for general intelligence where competitors create different agents that plays different unseen games. These games are written in a scripting language called Video Game Description Language. Every 40msec the agent should select one of the available actions. Like up, down, left, right, use button, nil which is do nothing. A game play trace is a sequence of actions.

Here are two videos that shows the difference between human player and MCTS agent. On the left you can see humans tends to go towards their goal and only do actions when necessary (for example only attack when monster is near). While MCTS agent on the right is stuck in the upper left corner moving in walls, attacking the air and walls.
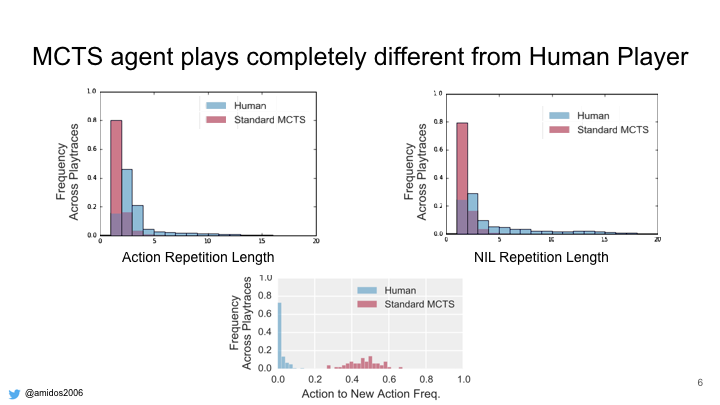
By analyzing the play traces for both human players and MCTS agent on different games. We found that humans tends to repeat the same action multiple times before changing. In the first graph it shows human have tendency to repeat the same action twice by 50%. Also humans tends to use more NILs and tends to repeat it more during the play trace. While in the third graph it shows the MCTS have a higher tendency to change actions more often than humans. Humans 70% of the time don’t change their action.
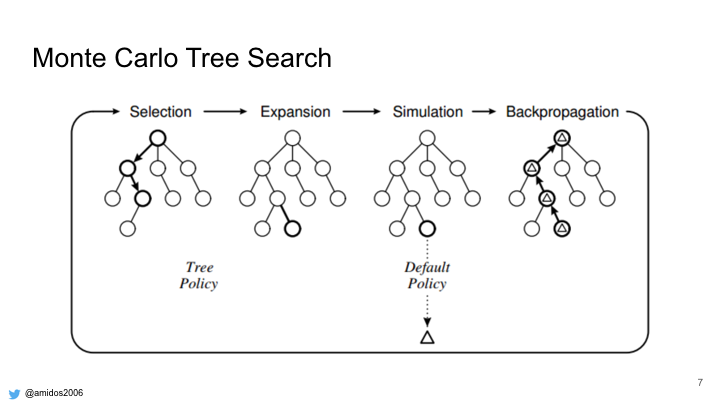
In order to achieve similar play traces, we need to modify MCTS. These are the main 4 steps for MCTS.
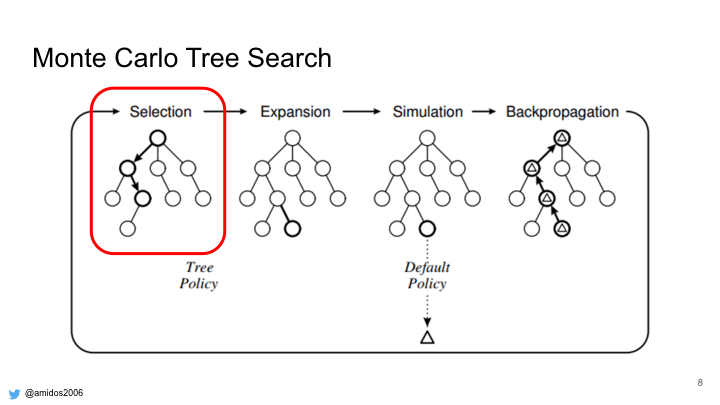
We tried to modify each step on its own but none of them have a big change in the distribution except for the selection step.
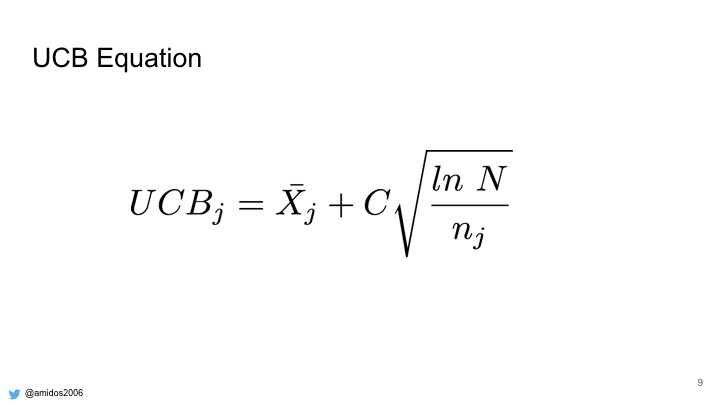
Selection step depends on UCB equation to select the next node.
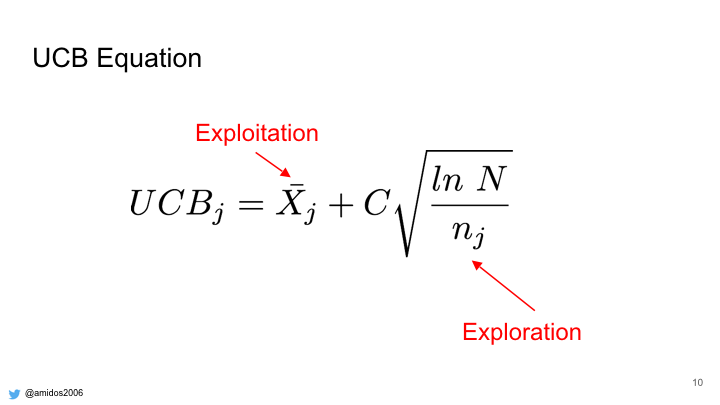
UCB equation consists of two terms, exploitation term and exploration term. The exploitation term bias the selection to select the best node while the exploration term push MCTS to explore less visited nodes.
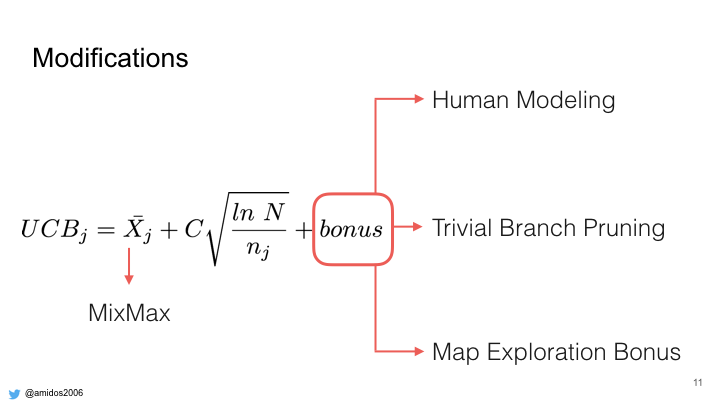
We modified the equation by adding a new bonus term which consists of 3 parts:
Human Modeling
Trivial Branch Pruning
Map Exploration Bonus
Also we modified the Exploitation term with a MixMax term.
We are going to explain all these terms in details in the upcoming slides.

We added a bonus value that shift the MCTS distribution to be similar to human distribution. As you see from the video the agent tends to repeat the same action and do more NILs with lower action to new action frequency. But as we see, it is still stupid, stuck in the corner, attacking air, moving into walls.

Thats why we added the second term which avoids selecting stupid nodes (like attacking walls and moving into walls) As we see the agent stopped attacking the air and whenever it get stuck in a wall, it changes the action or apply nil. But its still stuck in the corner.

So we added a bonus term that reward nodes that have less visited positions on the map. As we can see the agent now go every where and explore. But as we see the agent is coward, it avoids attacking the spiders.

So we used MixMax term instead of the exploitation term which use the mixture between the best value and the average value of the node instead of the average value only. As we can see the agent become courageous and moves towards the enemies and kill them.
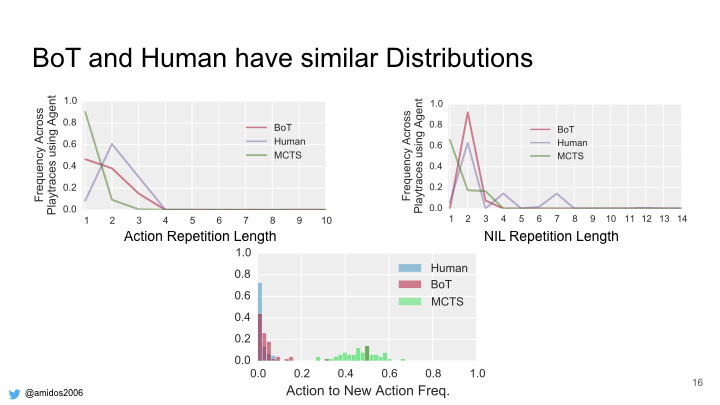
Analyzing the play traces after all these modifications. our BoT (Bag of Tricks) algorithm tends to be more similar to human compared to MCTS in action repetition, nil repetition. Also having less action to new action changes.

In order to verify these results we conducted a user study. In the study, each user watch two videos and he was to specify which is more likely to be human and why?
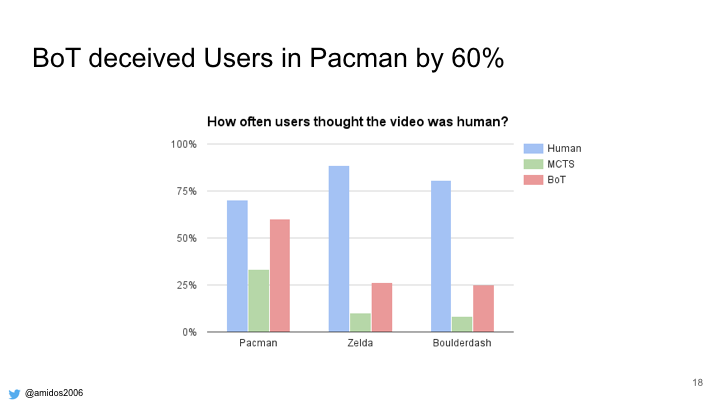
From the study our BoT algorithm was more human than MCTS but still not as good as humans, except for PacMan where deceived the humans by 60%.
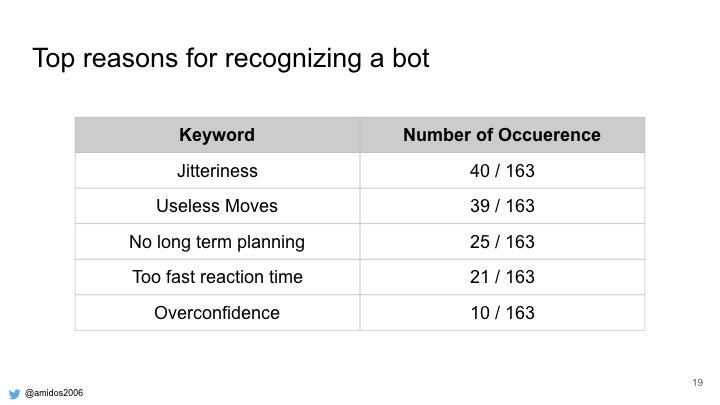
When we analyzed the human comments we found that the main reason for recognizing agent are the same as we stuff we tries to solve. Jitterness (changing directions very quickly), Useless moves (attacking walls, moving into them), No long term planning (stuck in one of the corners), too fast reaction time, over confidence (killing all enemies and become over achiever)

Thanks for listening.
That’s everything for now.
ByeBye